

Supongo que ya lo esperabas, luego no será ninguna sorpresa. Stockfish 8 ha sido incapaz de vencer a AlphaGo Zero en 100 partidas. Google DeepMind ha vuelto a demostrar que en un entorno cerrado con pocas reglas bien definidas el aprendizaje profundo no tiene competencia. Alpha Go Zero venció por 64 a 36 tras ganar 25 partidas jugando con blancas, 3 con negras y lograr tablas en las restantes 72 partidas. Te recuerdo que Stockfish 8 ganó en 2016 el TCEC (Top Chess Engine Championship) siendo uno de los motores de ajedrez más potentes del mundo.
Por supuesto me dirás que la victoria fue injusta. La versión de StockFish 8 que jugó contra AlphaZero no usaba la tabla de finales de 6 piezas de Syzygy, luego en los finales su actuación era deficiente. Además, el límite de un minuto por jugada impedía que StockFish 8 demostrara todo su potencial. Más aún, el ordenador de 64 núcleos en el que se ejecutó StockFish 8 no es el óptimo y una versión de 64 bits con un solo núcleo hubiera jugado mejor. A pesar de todo ello, que AlphaGo Zero jugando contra sí mismo haya necesitado solo 4 horas para descubrir el conocimiento humano sobre el ajedrez adquirido tras 1400 años y haya alcanzado un nivel similar a StockFish 8 es espeluznante. ¿Qué sería capaz de aprender jugando contra sí mismo durante 7 días? ¿Contratará Magnus Carlsen clases privadas con AlphaGo Zero?
El futuro que nos depara el aprendizaje no supervisado con refuerzo pone los pelos de punta. Por fortuna, solo en entornos cerrados con pocas reglas. Por ahora… El artículo es David Silver, Thomas Hubert, …, Demis Hassabis, “Mastering Chess and Shogi by Self-Play with a General Reinforcement Learning Algorithm,” arXiv:1712.01815 [cs.AI]; por cierto, si eres aficionado al ajedrez te recomiendo consultar las diez partidas de ejemplo que incluye el artículo (PGN). Más información en Eduardo Cáceres de la Calle, “AlphaZero derrota a StockFish 8 tras tan sólo 4 horas de auto-aprendizaje”, Ajedrez Cuéllar, 06 Dic 2017; Mike Klein, “Google’s AlphaZero Destroys Stockfish In 100-Game Match,” Chess.com, 06 Dec 2017; Tommaso Dorigo, “Alpha Zero Teaches Itself Chess 4 Hours, Then Beats Dad,” AQDS, 07 Dec 2017.
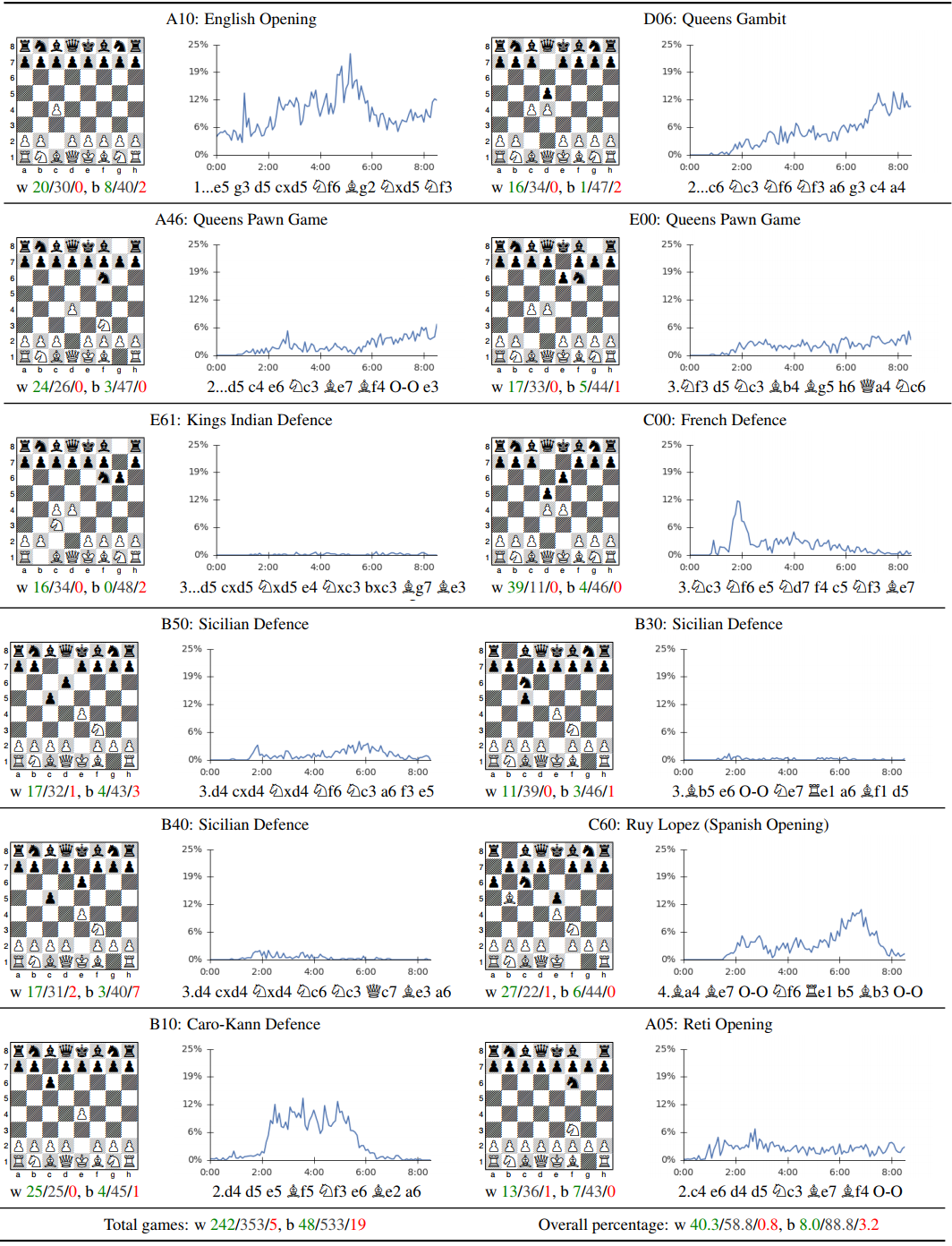
AlphaGo Zero ha redescubierto muchas aperturas, por ello se ha usado para analizar las 12 más populares entre humanos. El resultado es sorprendente, como muestra esta figura. Por ejemplo, a las 2 horas de aprendizaje casi siempre usaba tres aperturas, la inglesa, la Caro–Kann y la defensa francesa; en unos diez minutos descartó la defensa francesa y casi no la volvió a usar más; tras seis horas decidió prescindir también de la Caro–Kann; y tras ocho horas sus preferidas fueron la apertura inglesa y el gambito de dama. Toda una lección de ajedrez.
Los grandes maestros tendrán que estudiar las partidas de AlphaGo Zero y aprender de su sorprendente intuición ajedrecística. Como primeras conclusiones podemos destacar que ganar con blancas parece más fácil que con negras, y que la apertura inglesa y el gambito de dama son preferibles a las populares defensa india de rey y defensa siciliana. Además, parece que la fuerte dependencia de programas como Stockfish del estilo humano de juego es un lastre en lugar de una ventaja. Y finalmente, muchas reglas básicas del juego que todos los aficionados aprendemos (como enrocar el rey cuanto antes y evitar moverlo hasta superar el juego medio) no parecen ser las óptimas (AlphaGo Zero mueve el rey en cuanto puede para usarlo como un pieza más).
El algoritmo de Montecarlo tipo alfa-beta de Stockfish analiza unos 70 millones de posiciones por segundo, mientras que el de AlphaGo Zero solo analiza 80 mil posiciones. Para compensar este déficit usa su red de neuronas profunda (multicapa) para seleccionar las posiciones más prometedoras (lo que alguna gente ha bautizado como su “intuición tipo humana”).
En resumen, si eres aficionado al ajedrez te recomiendo consultar la opinión de los maestros y grandes maestros sobre el juego de AlphaGo Zero. Si no eres aficionado al ajedrez recuerda que las mejores inteligencias artificiales del mundo, ahora mismo, son muy torpes, pero muy torpes; jugar al ajedrez o al Go te puede parecer difícil, pero para una máquina es muy fácil; sin embargo, lo que tú haces todos los días y a todas horas en tu vida diaria es imposible para una máquina, ahora y hasta dentro de muchas décadas. ¡No lo olvides!
